Chúng tôi là OpenData
Tổ chức phi lợi nhuận thúc đẩy AI thông qua cung cấp dữ liệu huấn luyện chất lượng, tạo điều kiện cho các tổ chức, nhóm nghiên cứu có tài nguyên cần thiết để nghiên cứu, phát triển, và ứng dụng AI.


3+
200+
Nhân sự
Dự Án
AI Training Data
Chúng tôi khai thác và cung cấp dữ liệu huấn luyện các hệ thống AI
Khai thác Dữ liệu
Dữ liệu thô thu thập từ nhiều nguồn sẽ được xử lý, trích xuất để tạo ra nhưng bộ dataset có ý nghĩa, giàu thông tin giúp tăng cường hiệu năng các mô hình AI.


Hệ thống "đào" dữ liệu
OpenData cung cấp hệ thống khai thác dữ liệu dành với mục tiêu dễ tiếp cận với nhiều đối tượng từ nhiều linh vực, thu hút nguồn lực xã hội, tăng tốc việc phát triển AI.
Chúng tôi cam kết các dữ án sẽ được công bố dưới hình thức mã nguồn mở và phi thương mại với mục tiêu chính là giúp các tổ chức, nhóm nghiên cứu vượt qua giới hạn về dữ liệu để xây dựng các hệ thống AI mạnh mẽ hơn.
Sứ mệnh vì cộng đồng




Dự án dữ liệu AI
Danh sách các dự án đang phát triển


Vietnamese Image Captioning
Thu thập dữ liệu ảnh và captions có thể sử dụng cho các mô hình sinh ảnh, miêu tả ảnh, hỏi đáp hình ảnh, ...

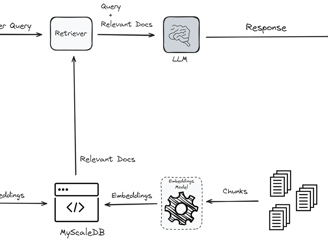
Vietnamese Text Embedding
Dữ liệu cặp văn bản tiêng việt để huấn luyện các mô hình text embedding cho general domain.




Natural text-speech dataset
Thu thập giọng đọc cho các hệ thống speech-to-text and text-to-speech
Onoging
...
→
→
→
→
Dữ liệu huấn luyện AI là tài nguyên quy giá và thường ít được chia sẻ, gây trở ngại lớn trong việc phát triển AI công bằng và có trách nhiệm. OpenData là dự án phi lợi nhuận đầu tiên hướng tới việc khai thác dữ liệu huấn luyện AI quy mô lớn.Dữ liệu được công khai, miễn phí sẽ là chất xúc tác đẩy nhanh tốc độ nghiên cứu và phát triển AI.
OpenData Team

★★★★★